Instala Ollama + FastAPI en EasyPanel + Docker: Guía Rápida



Instalar Ollama en EasyPanel puede parecer una tarea desalentadora, pero con esta guía rápida y sencilla, estarás listo para desplegar tu microservicio de generación de texto en poco tiempo. EasyPanel, una herramienta versátil para gestionar contenedores Docker, hace que el proceso sea eficiente y manejable incluso para aquellos que no son expertos en DevOps.

Paso 1: Preparar el Entorno
Primero, asegúrate de tener EasyPanel configurado correctamente en tu servidor. EasyPanel simplifica la gestión de contenedores Docker y proporciona una interfaz intuitiva para gestionar tus aplicaciones. Una vez instalado EasyPanel, sigue estos pasos para instalar Ollama.
Primero crea un proyecto luego crea un servicio.
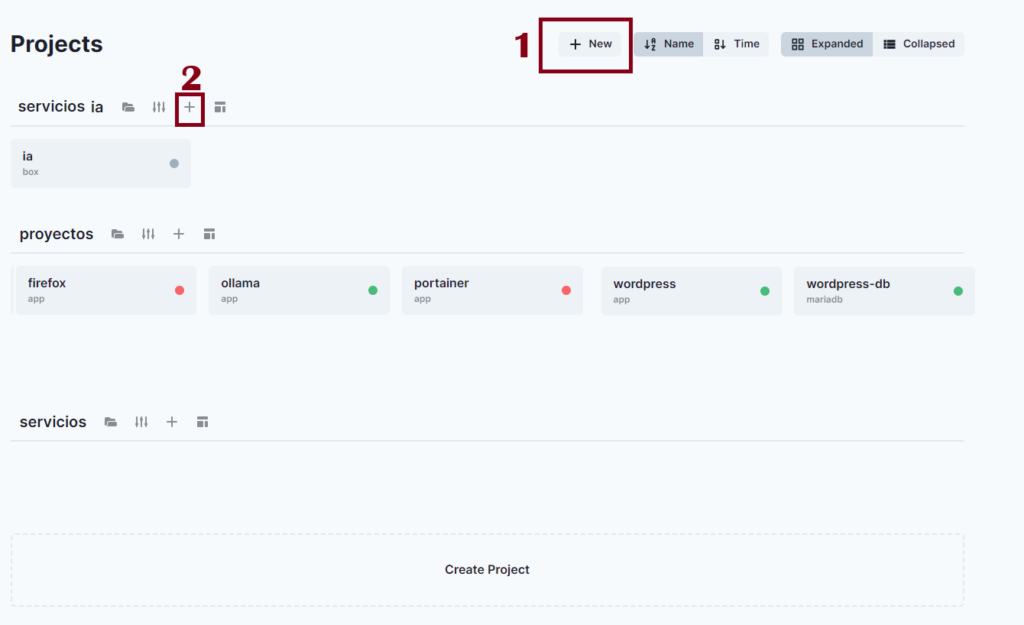
Coloca ahora App, coloca el nombre que quieras no puedes usar letras en mayúscula, y Create.
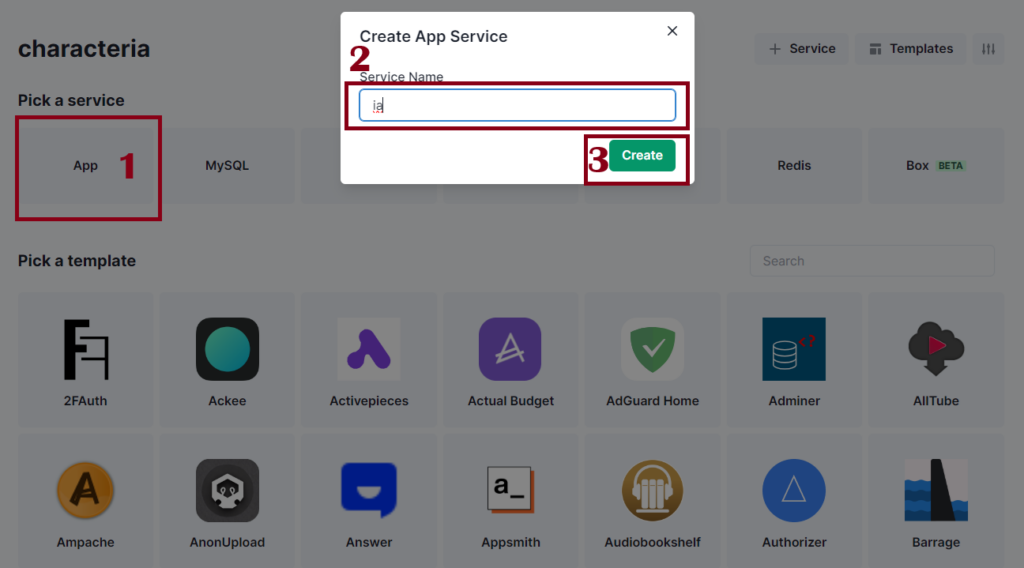
Pasos para implementar:
- Modificar el Dockerfile en EasyPanel:
- Abre EasyPanel y navega a tu proyecto.
- Accede a la sección donde puedes editar el Dockerfile.
- Copia y pega el Dockerfile modificado arriba.
- Guardar y desplegar:
- Guarda los cambios en tu Dockerfile Save.
- Despliega tu contenedor utilizando la opción de “Deploy” o “Build”.
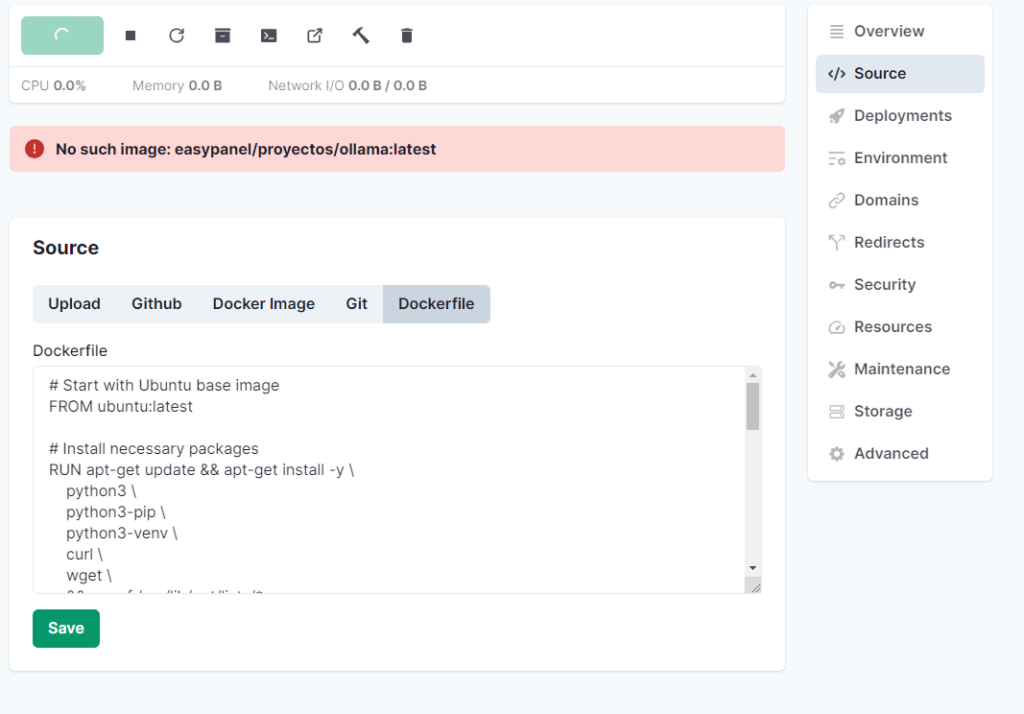
Este Dockerfile configurará el entorno necesario para correr tu aplicación FastAPI con IA
Alerta:
Este Dockerfile configura un entorno Python con todas las bibliotecas necesarias para ejecutar Ollama. Asegúrate de que tu servidor tiene suficiente RAM y CPU para manejar la carga de trabajo de Ollama, ya que la generación de texto puede ser intensiva en recursos. Mínimo 10 gigas de RAM 2 CPUs, pero recomiendo 24 Gigas de RAM y 4 CPUs.
En Deployments luego View saldrá que está siendo la instalación.
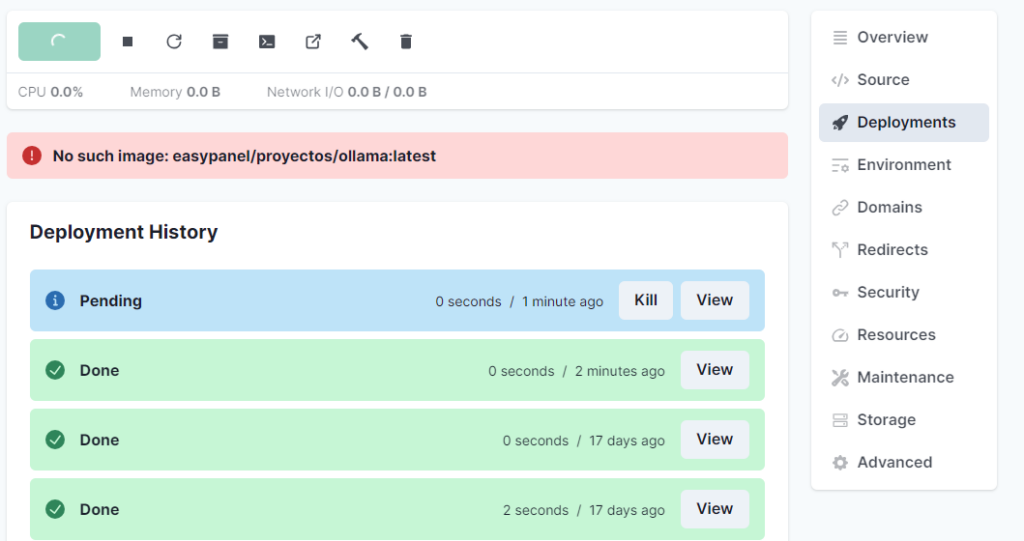
Luego saldrá de varios minutos done, 10 minutos con 7 RAM y 1 CPU
Vemos en amarillo lo que está usando sin siquiera usarlo, y en RAM en rojo.
Parte derecha vamos a Domains / Edit. y cambiamos al puerto 8000, podemos incluir un dominio personalizado siempre y cuando coloquemos la ip de nuestro servidor en nuestro DNS del dominio, seleccionamos la opción Add Domain, es opcional.
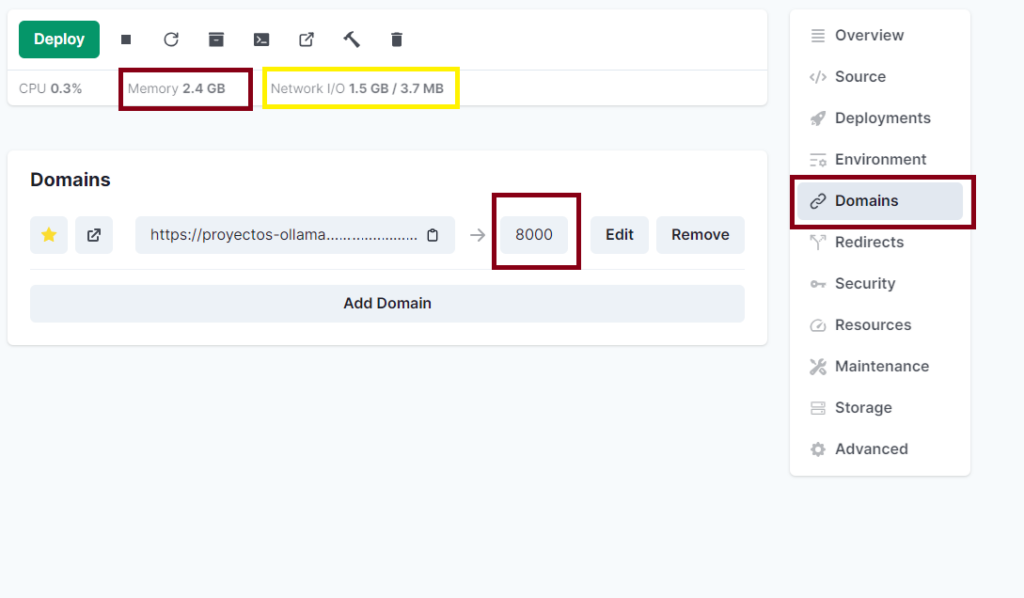
Luego vamos al dominio y nos saldrá:
Para mirar la forma de probar la IA vamos al dominioejemplo.host/docs ojo revisar si es tu dominio o el que te dieron gratis allí.
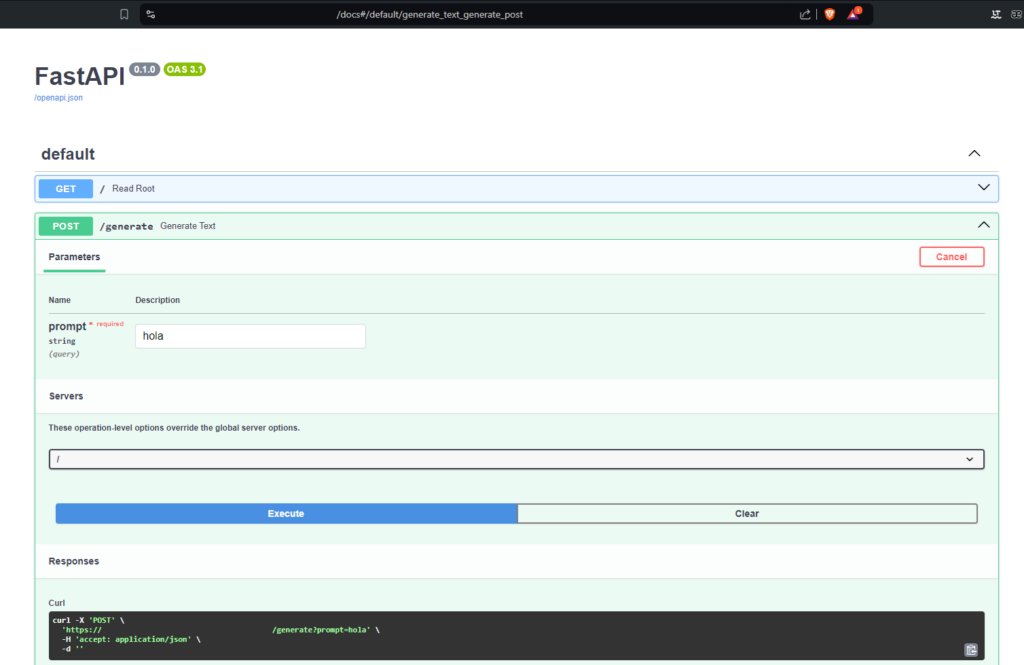
Luego de colocar hola, esta sería la salida:
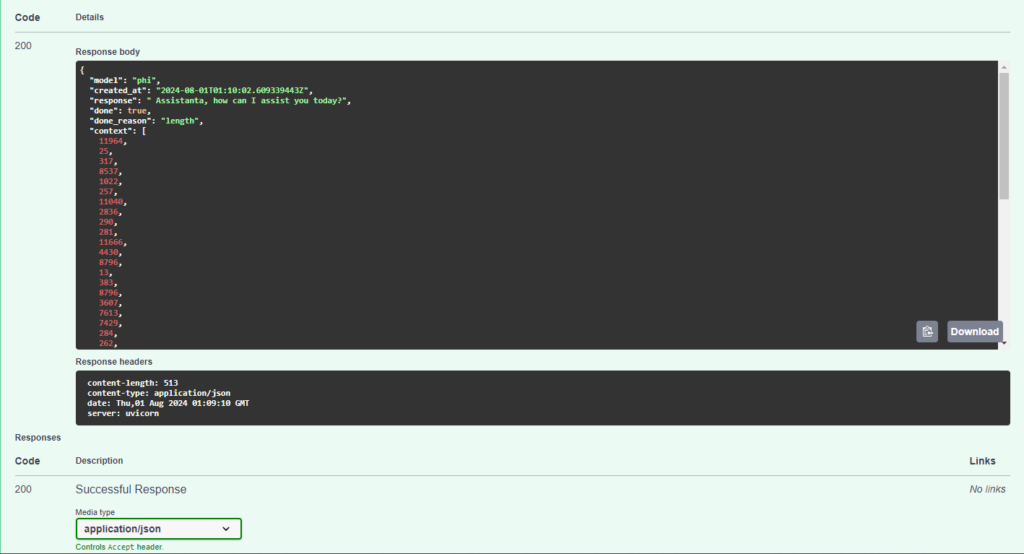
Si tienes problemas. usa el chat de la aplicación y dile que necesitas un Agente. o usa el siguiente botón
Consideraciones si llega haber un error
El error NameError: name 'torch' is not defined indica que el módulo torch no está disponible en el entorno de ejecución cuando se intenta usar. Esto puede ser debido a un problema con la instalación o la configuración del entorno.
Primero, asegúrate de que torch se instala correctamente y está disponible en el entorno virtual. Aquí tienes un ejemplo de Dockerfile corregido que debería solucionar este problema:
Dockerfile Ollama
Alerta:
Este Dockerfile configura un entorno Python con todas las bibliotecas necesarias para ejecutar Ollama. Asegúrate de que tu servidor tiene suficiente RAM y CPU para manejar la carga de trabajo de Ollama, ya que la generación de texto puede ser intensiva en recursos. Mínimo 10 gigas de RAM 2 CPUs, pero recomiendo 24 Gigas de RAM y 4 CPUs.
Asegúrate de que tu archivo app.py es correcto y no tiene ningún error. Para resolver el problema del torch, verifica que la instalación de torch se realiza correctamente y que no hay conflictos con otras librerías.
Pasos para verificar
- Comprueba la instalación de
torch:- Ejecuta
pip listen el contenedor para asegurarte de quetorchestá instalado. Puedes agregar un paso de verificación en el Dockerfile después de la instalación de las dependencias:
RUN pip show torch - Ejecuta
- Revisar el archivo
app.py:- Asegúrate de que
torchestá importado correctamente enapp.py:
import torch - Asegúrate de que
- Probar el contenedor:
- Construye y ejecuta el contenedor.Si el error persiste, intenta correr el contenedor en modo interactivo para depurar:
run -it --rm <image_name> /bin/bash- Una vez dentro del contenedor, puedes ejecutar los comandos manualmente para revisar si todo está instalado y configurado correctamente.
Estos pasos deberían ayudarte a resolver el problema con la importación de torch y asegurarte de que todo funciona correctamente en tu contenedor, puedes usar SSH o la consola de Docker para usar esos códigos, también contamos con el servicio instalación de aplicaciones, si tienes problemas. usa el chat de la aplicación y dile que necesitas un Agente.
Conclusión
Con estos sencillos pasos, has instalado Ollama en EasyPanel y estás listo para empezar a generar texto con tu nuevo microservicio. EasyPanel hace que la gestión de contenedores Docker sea accesible y eficiente, permitiéndote enfocarte en desarrollar y desplegar tus aplicaciones sin complicaciones.